
随着 Anthropic 发布 Dynamic Workflows,允许单个指令触发数百个子 Agent 并行执行,整个 AI 圈似乎又一次陷入了宏大叙事的狂欢。为了构建这些复杂的“智能体集群”,开发者们习惯性地搬出了压箱底的“微服务全家桶”:用 Kafka 做消息队列,用 Redis 做短期记忆和状态锁,用 PostgreSQL 存储长期状态。
然而,在这一切的狂欢背后,工程界正在悄然发生一场截然相反的“反叛”。
本周,一篇名为《SQLite Is All You Need For Durable Workflows》的文章登顶了 Hacker News。文章指出了一个令许多架构师感到刺痛的事实:当你为了支撑几十个并发的 Agent,而花掉 80% 的精力去维护一堆分布式中间件时,你大概率是把问题搞错了。
在 AI Agent 这个全新的应用范式下,微服务架构不仅是杀鸡用牛刀,更可能是一剂毒药。而那个通常被认为是“玩具”或“移动端专用”的单文件数据库——SQLite,正在成为重塑 Agent 基础设施的完美答案。
一、剥开 Agent 的本质:为什么分布式是伪需求?
在传统的 Web 服务中,我们使用分布式中间件是为了应对突发的海量并发(High Throughput)。十万用户同时抢购一件商品,你必须依赖 Redis 的原子减库存,依赖 Kafka 的削峰填谷。
但 AI Agent 的工作流,其物理特性与高并发 Web 业务截然不同。
首先,绝大多数 Agent 是“单体焦点(Single-Tenant Focus)”的。当你委派一个 Agent 去阅读一份 10 万字的 PDF 并提取财报数据,或者让它去分析一个 GitHub 仓库的 Bug 时,这个漫长的推理链(Think -> Act -> Observe)是完全服务于单次调用的。它极少需要和其他 Agent 产生跨服务器的高频“事务级”竞争。
其次,延迟(Latency)比吞吐量(Throughput)更致命。大模型 API 本身已经非常慢,一次长上下文调用动辄耗时数秒甚至十几秒。如果在 Agent 的每一次状态转移中,你还要通过网络去连接远端的 Redis 或 Postgres,网络抖动和序列化开销将严重拖慢整体思考循环。
在 Agent 的世界里,本地化(Local-first)就是最高优的工程解法。SQLite 将昂贵的网络通信降维打击成了进程内的内存拷贝和磁盘写。消除了“网络分区(Network Partition)”的风险后,你的 Agent 获得了前所未有的健壮性。
二、硬核剖析:SQLite 如何胜任复杂工作流引擎?
有人会问:“SQLite 只有一个文件,并发一高就会锁库(Database is locked),怎么可能支撑复杂的调度和并行?”
这往往是对 SQLite 的刻板印象。只要开启正确的配置,SQLite 足以在单节点扛住数万 QPS 的读写。
1. 破解并发魔咒:WAL 模式 (Write-Ahead Logging)
早期的 SQLite 采用的是传统的 Journal 回滚模式,读操作和写操作会互相阻塞。但如果你执行 PRAGMA journal_mode=WAL;,一切就改变了。
在 WAL 模式下,SQLite 实现了真正的“读写分离”——读操作不会阻塞写操作,写操作也不会阻塞读操作。配合毫秒级的 NVMe 固态硬盘,单进程内的 SQLite 写入性能完全可以满足数百个并行子 Agent 的状态更新需求。
2. 实现原子的无锁消息队列
很多开发者认为必须用 RabbitMQ 才能实现可靠的任务重试。事实上,在 SQLite 中,只需一张极简的表和一个高级 SQL 语句:
CREATE TABLE tasks (
id TEXT PRIMARY KEY,
payload JSON,
status TEXT DEFAULT 'pending',
retry_count INTEGER DEFAULT 0,
next_retry_at INTEGER DEFAULT 0
);
当 Agent Worker 需要申领任务时,如何避免多个进程拿到同一个任务?利用 SQLite 原生支持的 RETURNING 子句,你可以实现原子级的 Pop 操作:
UPDATE tasks
SET status = 'processing'
WHERE id = (
SELECT id FROM tasks
WHERE status = 'pending' AND next_retry_at <= unixepoch()
ORDER BY next_retry_at ASC LIMIT 1
)
RETURNING *;
这一行查询不仅锁定了任务,还直接返回了数据,全程无需借助任何分布式锁机制。
3. 状态机的“时间旅行”与持久化回滚
Agent 执行任务时常会遭遇 API 503 限流或莫名其妙的幻觉崩溃。在分布式系统中,回滚缓存、数据库和消息队列的一致性是一场噩梦。但在 SQLite 里,Agent 的全部上下文记忆和执行状态都在一个文件里。
利用 SQLite 严格的单机 ACID 事务,你可以在执行敏感动作前打一个 Savepoint。一旦 Agent 崩溃,重启后它可以立即从该断点完美复活,一切就像没有发生过错误一样。
三、部署与运维的降维打击
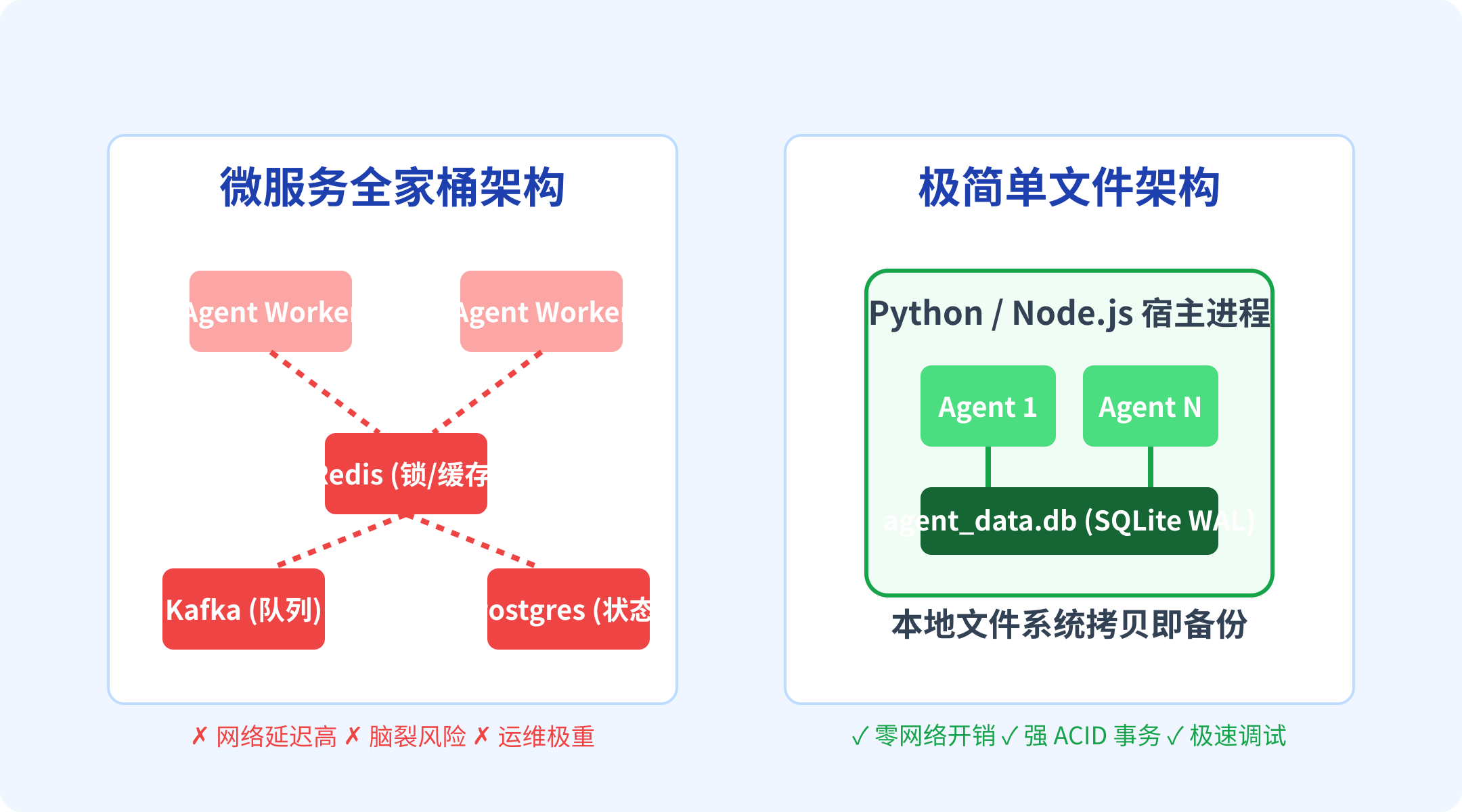
当我们将微服务架构与 SQLite 单体架构进行成本对比时,差距令人咋舌。
- 部署成本:在 K8s 上拉起一套 Kafka + Redis + Postgres 集群需要数 GB 的内存预留和数周的运维调优;而 SQLite 只是一个零依赖的 C 库,集成在你的 Python 或 Node.js 进程中。
- 可观测性:调试分布式系统需要在不同组件中追踪 Trace ID;调试 SQLite 只需要打开一个本地图形化工具查询
.db文件。 - 状态的可迁移性:这是最性感的一点。如果你的 Agent 在远程服务器上陷入了某个奇怪的死循环,你只需要用
scp把agent_data.db拷贝到本地。你拥有了那一刻系统完整的快照,可以在本地完美复现并调试 Bug。这在分布式系统中是根本不可想象的。
结语:在 AI 泡沫中找回工程理性
科技行业总是在钟摆的两端摇摆。在 AI 厂商拼命卷模型参数、造出越来越花哨的 Agent 编排框架时,一线工程师正在悄悄用脚投票。
SQLite 的复兴,不仅仅是因为它是一个优秀的数据库,更是因为它代表了一种“少即是多(Less is More)”的工程哲学。
在充满着不确定性、API 调用频繁失败的 AI 时代,我们最需要的其实不是“能支撑亿级并发的海量吞吐”,而是“确定的执行、极低的维护成本和快速的失败恢复”。
未来的高级架构师,或许不是那个能把系统设计得最复杂、图纸画得最宏大的人;而是那个敢于在所有人都在堆砌微服务时,克制地说出“一张 SQLite 表就够了”的人。
附:配图生成思路记录
- 配图 1 (Cover): 抽象极简主义。左侧是一团极其复杂发光的线缆纠缠成的球体(代表分布式全家桶);右侧是一块切割完美的、发着微光的实心金属立方体(代表 SQLite)。
- 配图 2 (对比图): 上方是微服务架构(多节点之间的红色高延迟网络连线),下方是 SQLite 架构(进程内蓝色的高速内存流转)。
