
把照片冲洗出来的写法:模型还能这样吐字
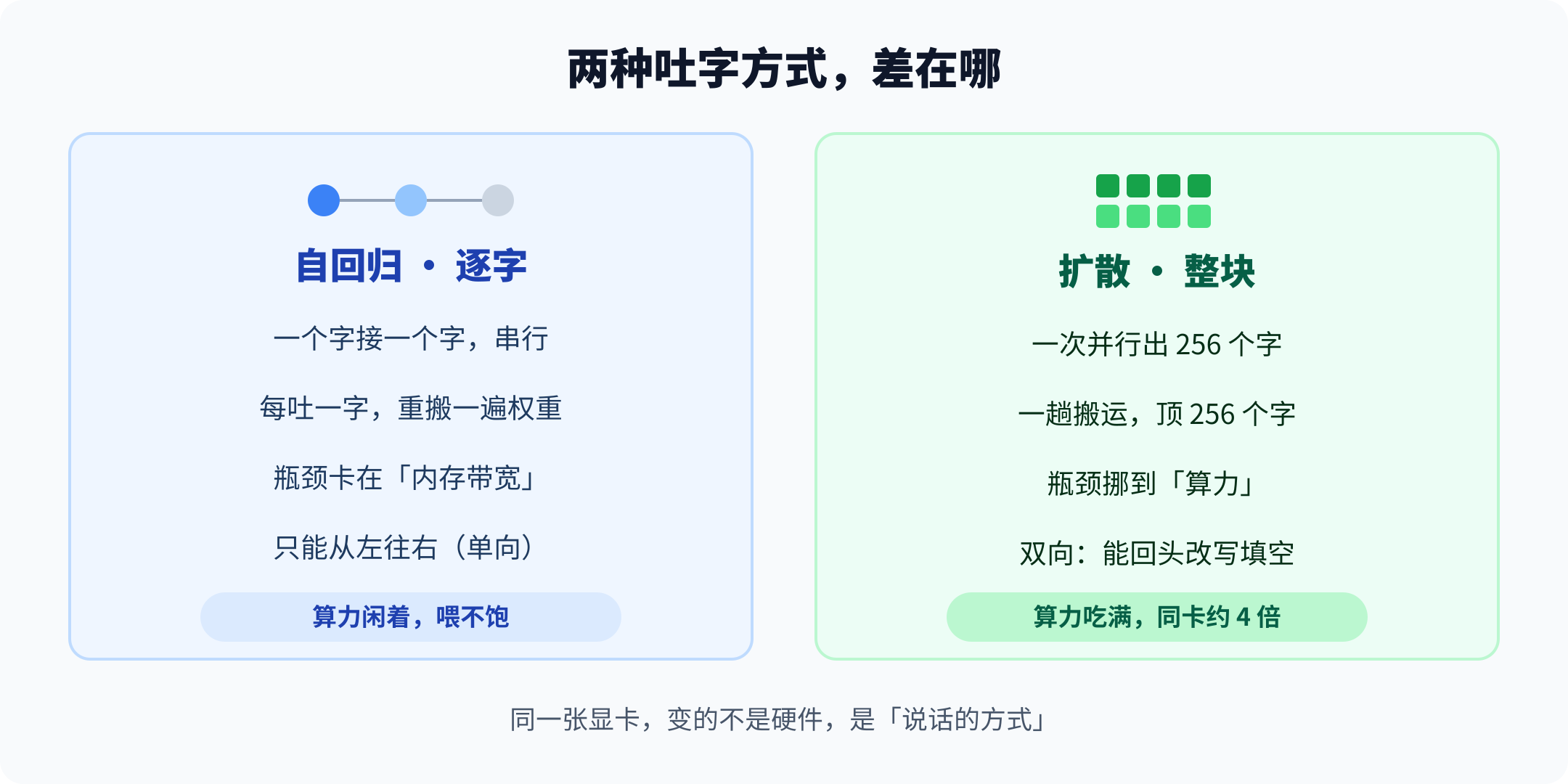
你问大模型一个问题,答案是一个字一个字蹦出来的。屏幕上字往外冒的样子,是它真在逐字计算,背后并没有什么打字机动画。专业说法叫自回归:从左到右,每生成一个 token(差不多一个字或半个词),都要把这个新字塞回去当输入,再算下一个。第三个字必须等第二个字定下来,第二个字必须等第一个字定下来。一句话排着队过独木桥。
要让它快起来,常规思路就两条:换更猛的卡,或者换更小的模型。一个东西跑得慢,要么引擎不行,要么车太重——这是我们对"快"的默认理解。
谷歌 2026 年 6 月放出的一个实验性开源模型换了条路:同一张卡,生成快了约 4 倍。它不再排队吐字,而是像冲洗照片,先把一整块文本"糊"出来——一片噪点,啥也看不清——再一遍遍修清楚,直到字句浮现。要理解这 4 倍从哪来,得先看清逐字生成到底慢在哪。
真正拖慢它的,是那几十 GB 权重的反复搬运
直觉会说,生成慢是因为算得多。但你拿监控盯着 GPU 看,会发现一个别扭的事实:生成文本时,那张卡的算力单元常常闲着,真正满载的是显存到芯片之间那条数据通道。
道理在于,每吐一个字,模型都要把自己庞大的权重从显存里完整搬一遍,喂给计算单元。一个几十 GB 的模型,生成一句二十个字的话,就要把这几十 GB 搬二十趟。算一个字的乘加运算其实没多少,时间全耗在"搬"上了。这就是被内存带宽卡住——瓶颈不在算得快不快,而在数据喂得快不快。算力像一个饭量很大的人,却被一根细吸管喂饭,再能吃也没用。
所以逐字生成有个尴尬:你买更强的算力,可能根本提不了速,因为限制你的那根吸管没变粗。
整块一起去噪,等于把那根吸管的活儿摊给了过剩的算力
扩散式生成绕开了这根吸管。它不逐字吐,而是一次并行处理一整块——比如每次前向生成 256 个 token,所有 token 一起算。权重还是那些权重,但这一趟搬运同时顶了 256 个字的活,摊到每个字头上就便宜多了。搬运的总趟数被狠狠压下来,瓶颈就从"喂数据"挪回到"做运算"。而运算能力,恰恰是平时过剩的那部分。把活儿摊给闲着的算力,卡才算被喂饱。
数字很实在:单张 H100 每秒 1000 多 token,消费级的 RTX 5090 也有每秒 700 多。模型本身是个 26B 总参数的 MoE,推理时只激活 3.8B——MoE 就是一大堆专家分工,每次只叫醒其中几个干活,所以参数总量大、实际算的少。量化之后能塞进 18GB 显存的高端消费卡,也就是说这套东西真能在自己机器上跑起来,不只是云端演示。
因为它能回头看,所以天生会改写和填空
逐字生成还有个出身限制:只能从左往右,后面的字看不见前面没定的,更别说还没生成的。这让它写顺序叙述很自然,但碰上"在中间补一段"“把这句改通顺”"这段代码缺个函数体填进去"就别扭——它天生不会回头。
扩散式因为整块一起处理,每个 token 都能看到块里其它所有 token,包括它"后面"的。这叫双向注意力。它一边迭代一边把整块拿来重新评估,发现哪儿不对当场修掉。于是改写、代码的填空补全、那种非线性展开的结构,反倒成了它的顺手活——而这些正好是从左往右那套的弱项,顺带把这个老毛病也治了。
那要不要全换成扩散,现在还不到时候
这是个实验阶段的模型,要论最高质量的生产输出——那种你要发出去、要负责任的长文和复杂推理——目前仍然是自回归的天下。扩散式现在的强项很集中:速度敏感、要来回交互的本地场景,在线编辑、快速迭代、补全填空。
那以后怎么判断该用哪种?看一件事:你手上这活是"一锤子要质量",还是"高频次要响应"。前者,比如生成一份正式文档、做一段需要严谨推理的回答,自回归的稳更划算;后者,比如编辑器里随手补全、对着一段文字反复改,扩散的快和能回头改才用得上。还有一条:需要"回头"的活——填空、改写、非线性编辑——扩散有结构性优势;纯顺序往下写的,两者差距没那么大。
回过头看,“快"这个词被我们想窄了。提速不止换卡和换小模型两条路,连"从左到右一个字一个字写"这个生成方式本身,都是可以换掉的变量。下次再看到"某模型更快了”,先分清一件事:它是换了硬件,还是改掉了"从左往右写"这件事——这俩快法,根子完全不同。
