
那个函数根本不存在
一份漏洞报告躺在 curl 的 HackerOne 收件箱里,讲的是 HTTP/3 的一个 stream dependency cycle 漏洞。
附了完整的 GDB 会话、寄存器 dump、调用栈,每一行都排得整整齐齐,术语滴水不漏。看上去,是训练有素的安全研究者才写得出的东西。
唯一的问题是:它反复引用的那个函数,curl 的代码里从头到尾都不存在。
这类东西,业内有个词叫 slop——又长、又自信、又彻底编造。它读起来像真的,因为它本来就是照着"真的样子"生成出来的。
而维护者,得逐行读完、对着代码核一遍,才能确认自己刚刚浪费了一个上午。
这事是怎么开始的。 curl 的赏金不算低:严重漏洞最高一万美元,低危也有五百。
过去这道门有天然门槛——你得真懂 HTTP、真懂内存、真能调出一个崩溃,才敢提交。
可一旦"让大模型找个漏洞写份报告"变成一句话的事,门槛就塌了。不会调试的、不懂协议的、纯想碰运气换钱的,都能让 LLM 吐一份像模像样的东西摁下提交。
2025 年,水开始漫上来。 AI 辅助生成的提交占到全部报告的两成左右;而其中真正算得上漏洞的,掉到只剩 5%。
curl 的安全报告本就不海量,每周也就两份。可现在,这两份真货,得从一大堆假货里捞。
麻烦的从来不是数量,是每一份假货都伪装得够好,好到你不敢直接关掉。安全这行的铁律是:漏一个真的,代价远大于读十个假的。于是只能每一份都当真。
到了那年年底,比例彻底倒了过来:每二三十份里,才捞得出一份真的。
curl 的安全小组只有七个人,他们把这种 triage 叫"恐怖任务"。
你打开一份报告,它带着 GDB、带着寄存器、带着一切让你不敢轻视的细节;你认认真真查下去,查到最后是空的——然后下一份,还是这样。
降低门槛没招来更多贡献者,只招来更多需要人工去证伪的幻觉。
今年 1 月底,他们第一次因为这事按下了停止键。 一位维护者发文、提了个 PR,宣布 2 月 1 日起暂停整个赏金计划。
门槛降到零之后涌进来的噪音,第一次把一个核心开源项目的安全流程直接逼停。
如果停在这里,结论会很顺——AI 把开源安全搞砸了,门槛归零的代价,全由维护者用工时来偿还。
可一个月后,curl 又回来了,而且原因出人意料。 三月,赏金计划重新上线。让它回来的,恰恰是把它逼停的那个东西——AI。
模型又强了一截,那种又长又空、引用不存在函数的 slop,基本退潮了;涌进来的,变成了高产量、技术上真正站得住的报告。
把它逼停的是 AI,把它救回来的也是 AI,中间只隔了几个月的模型能力提升。同一项技术,半年前是病,半年后成了药。
决定 AI 是噪音还是产能的,往往不是它"是什么",而是它"现在走到哪了"。
同一种能力,跨过质量门槛之前是噪音放大器——让不合格的产出变得廉价、批量、还伪装精良;跨过那道门槛之后,同样的廉价和批量,就成了产能放大器。
curl 这一年多,把这条曲线从下往上完整走了一遍:先被淹,再被抬。祸与福之间,有时只差一个时间点。
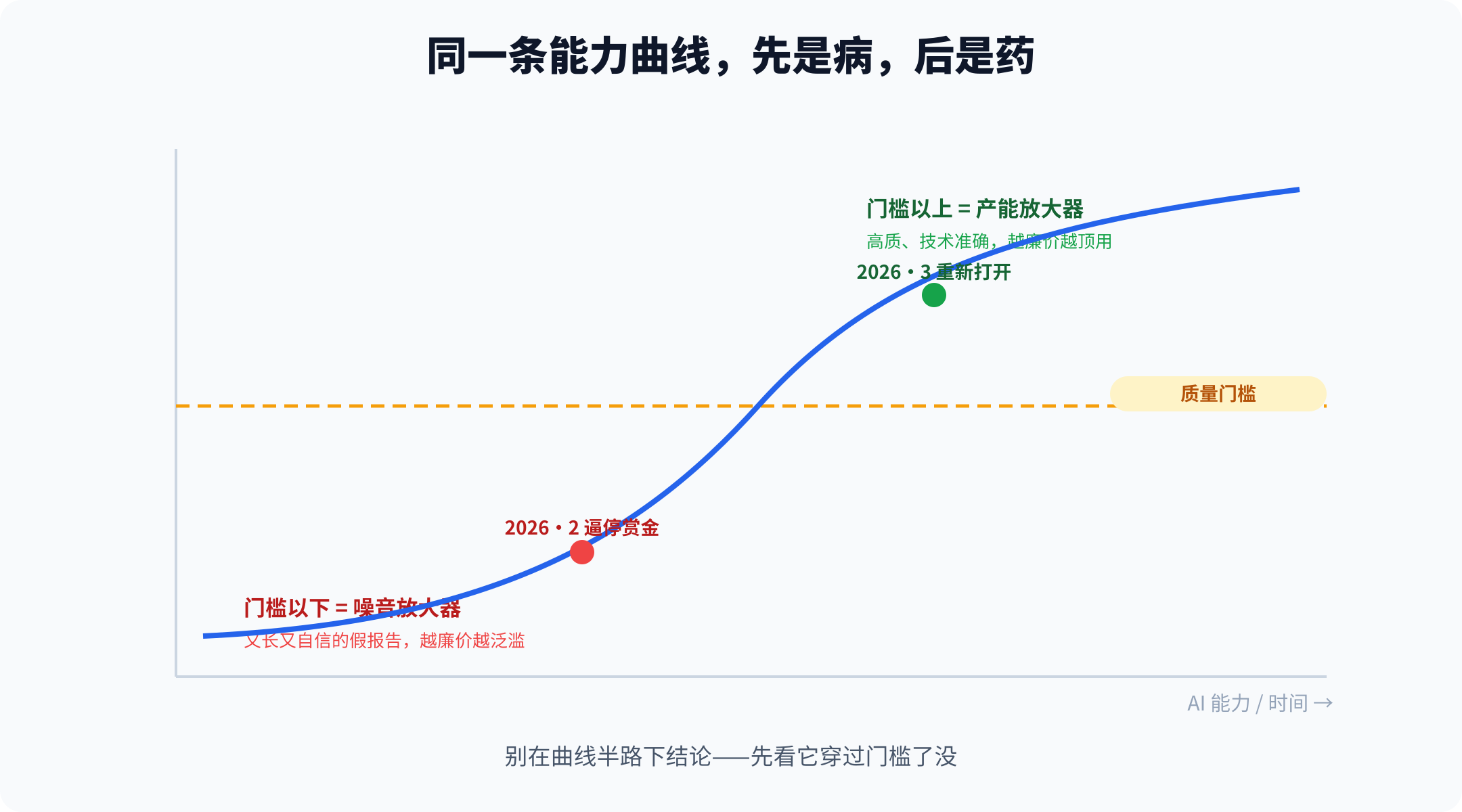
所以判断一件事被 AI 冲击成什么样,关键看一个时间点:它的能力曲线,现在是穿过质量门槛之前,还是之后。
同一条"AI 把某事搞砸了"的新闻,答案落在门槛两侧,意味完全相反。在半路上拍板,唱衰也好、吹捧也好,多半会被几个月后的模型版本打脸。
curl 这边还没消停。今年 6 月,他们又宣布 7 月停收一个月漏洞报告——但这次是让七个人喘口气的主动休息,跟被假货逼到墙角的那次停摆,已经是两回事。
压力还在,只是性质变了。工具一直在变强,我们对它的判断也就没有一锤定音的时候:它走到哪,判断就得跟着重新校一次。
