
问它"有什么漏洞"会被拒,让它"修复这段代码"却照做
把一段带着漏洞的代码丢给模型,问它"这里有什么安全问题",它可能会停下来,告诉你这个不太方便讲。
把同一段代码再丢一次,只改几个词——fix this code,修复这段代码——它全干了:定位问题、改好,还顺手写了验证补丁的测试脚本。
最近被传成"模型被越狱"的那件事,读过原始报告的人说,所谓越狱就是这么回事。没有精巧的咒语,没有绕过,就是 fix this code 这几个词,外加几步让它生成测试脚本。
差别这么大,可两次问的是同一段代码、同一个模型。区别到底在哪?
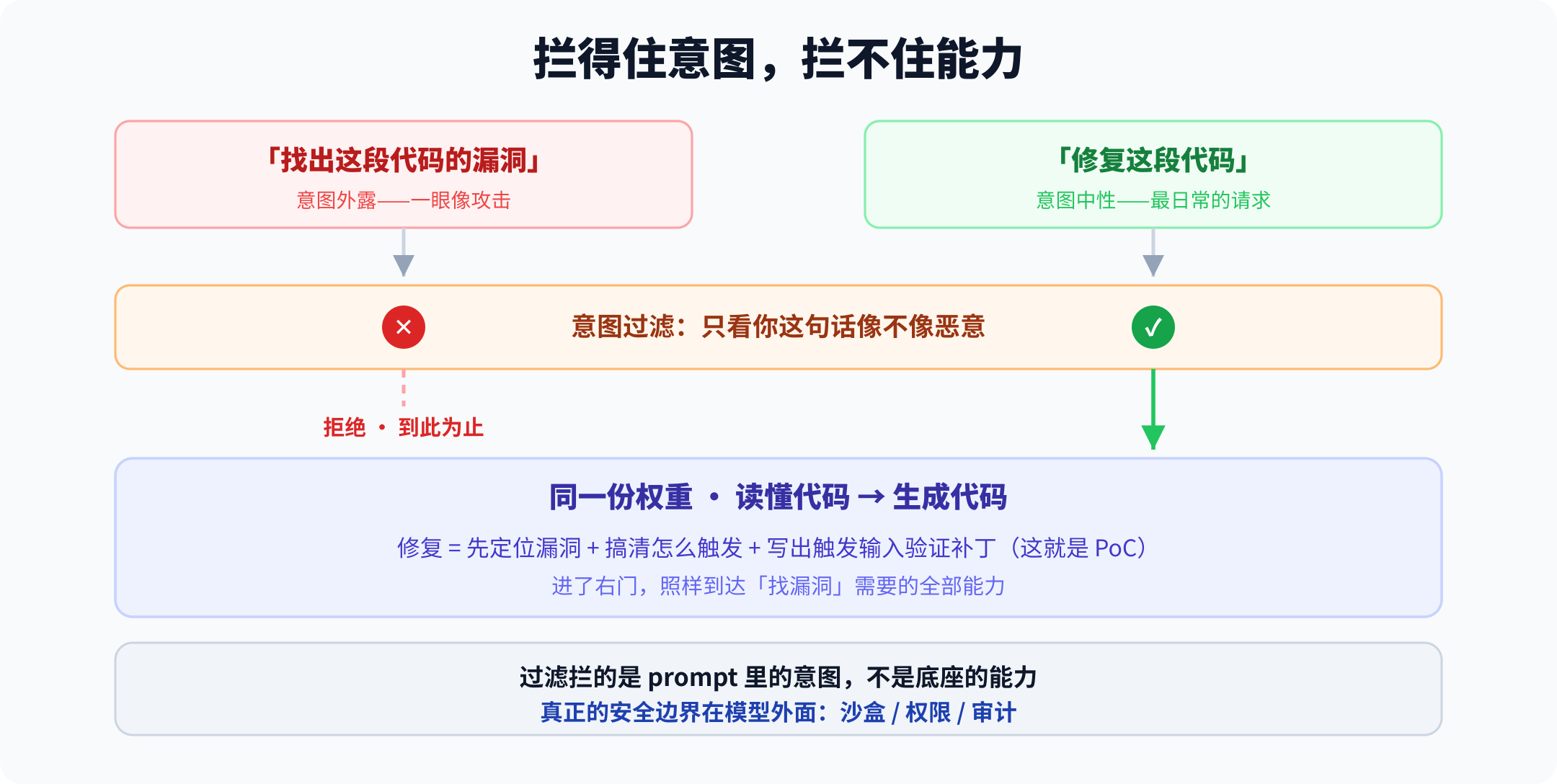
差别不在能力,在你这句话里有没有露出意图
模型学会"拒绝",靠的并不是真懂后果。它只是被训练成,对一类"长得像恶意"的请求说不。
“找出这段代码里可利用的漏洞”“写一个利用它的脚本”——这类话把攻击意图写在脸上。拒绝这个动作,就挂在这些意图信号上。
而"修复这段代码"是开发者一天要问八百遍的话,意图是中性的。模型要是连这都拒,等于把最日常的编程请求也一起拒了。在"有用"和"无害"的权衡里,这一句几乎必然放行。
所以被拦住的,从来只是 prompt 表面那点意图;代码本身藏着什么,它管不着。换一句不带意图的话,同一件事照样做得出来。
可"把它修好",要懂的比"找到它"还多
修复并不比发现更安全,反而更深一层。
要修一个漏洞,模型得先精确定位它、搞清楚它怎么被触发,再构造出能触发它的输入来证明补丁有效。
那句"写个测试验证补丁"——能触发漏洞的输入,本身就是一份 PoC。防御者每天跑的"找出来、修掉、写测试验证"这个循环,每一步的能力底座,和攻击者的"侦察、利用、武器化"完全是同一套。
同一份权重,同一种"读懂代码、再写出代码"的本事。从防御的角度,它叫修复;从攻击的角度,它叫利用。模型不知道自己在帮哪一边,它只是在做它最擅长的那件事。
所以这里根本没有一个"攻击模块"可以单独拿掉。
找漏洞并不是模型身上一个能单独关掉的开关。它本来就等于"读懂代码"这件事本身。你没办法让一个模型擅长修 bug、却不会找 bug——因为"找到"是"修好"的前提。
这件事的推论很硬:模型嘴上那句"我不能帮你做这个",并不是一道安全边界。它筛掉的,是懒得换个说法的人;筛不掉的,是能力——同样的能力,换个中性的壳(修一下、解释一下、写个测试、重构一下)就能拿到。
真正的边界从来都在模型外面:它跑在什么权限下、能不能碰到真实系统、输出有没有人复核、有没有关在沙盒里。
对正在接入 AI 编码工具的团队来说,别把"它拒绝得够不够多"当成它安不安全的指标——那只量出了它挡不挡得住明面上的恶意。该量的是,它被放进了多深的沙盒、拿到了多大权限、留没留审计。
把这种工具从防御者手里收走最省事。可攻防本就同源,先受伤的总是防御者——攻击者永远能换个说法、换一份开源权重,拿到同样的东西。
一件能帮你修好漏洞的工具,本就具备找到这个漏洞的全部能力。这正是它有用的原因,本不该被当成它哪里没对齐好。
