
首页写省 120 倍 token,我翻了论文:跨 31 个仓库平均是 10 倍
接手一个十几万行的老项目,你让 Claude Code 帮你查一句"这个支付回调,到底是谁在调它、改了会炸到哪几个服务",盯着它干活,你看到了什么?
它 grep 一个函数名,翻出三十个文件,挨个 read 进上下文,顺着 import 再 grep,再 read,来回十几二十轮。等它终于把调用链拼出来,这一轮对话的 token 已经烧掉大半;下一段对话窗口一清空,它又得从头来一遍。
很多人以为这是上下文窗口不够长,于是盼着 200K、1M 的窗口。但窗口再大也救不了:每次它都把整个文件当成"未知"从头读一遍,读过的关系一条都没留下。同一条调用链,昨天读过、上午读过、这条对话里也读过,换一段对话它还是不认识。
这周 GitHub 趋势榜上有个叫 codebase-memory-mcp 的工具,专治这件事:与其让 Agent 每次现读现拼,不如先把代码库解析成一张图常驻本地,结构问题直接查图。
它把代码变成了一张能查的图
机制不玄。它先用 tree-sitter 把代码扫成 AST(语法树),抽出每个函数、类、import、调用;对 Python、TypeScript、Go、Rust 等十几种主流语言,再叠一层 LSP 做类型解析,把 import 和泛型这些 tree-sitter 单独对不上的引用接上号。
最后落成一张知识图谱:节点是函数、类、HTTP 路由,边是"谁调用谁"“跨服务怎么连”。连 Dockerfile、K8s manifest 都被建成图里的节点。建图这一程全在内存里跑(LZ4 压缩 + 内存里的 SQLite),索引完就把这部分内存放掉;图本身落成本地数据库常驻,之后查的就是它。
于是"谁调用了这个函数"“改这里影响哪些符号”"这仓库架构长什么样"这类问题,不再是几十轮 grep+read,而是一次图查询。官方给的数:结构查询亚毫秒返回;Linux 内核 2800 万行、7 万 5 千个文件全量索引 3 分钟;一般仓库毫秒级就建完。
它配了十几个 MCP 工具:搜图、追调用链、把你还没提交的改动映射到受影响的符号、跑 Cypher 查询、查死代码。装它就一行命令,安装器自己检测你机器上的 Claude Code、Codex CLI、Gemini CLI 等十来个 Agent,把各自的配置写好:
curl -fsSL https://raw.githubusercontent.com/DeusData/codebase-memory-mcp/main/install.sh | bash
装完开 config set auto_index true,会话启动自动索引、git 变更增量更新。一行 curl 直接管道给 bash 终究是把远程脚本拿来就跑,介意的话仓库 release 里有签名加校验和的二进制,下载核对 checksum 再手动装更稳。
但首页那个 120 倍,是一个样本
它首页挂着一句很抓眼的话:结构化查询比逐文件搜索省 120 倍 token。
我去把这个数翻清楚了。这 120 倍来自一个具体例子:5 个结构化查询大约花 3400 token,对比文件逐读大约 41 万 token——折算下来是省掉 99% 还多。一个例子、5 次查询、一次对比——这是 best case,是把"图查询最划算的那个场景"挑出来给你看。
真正该拿去算账的数,在它自己的 arXiv 预印本里。跨 31 个真实仓库实测:答案质量 83%,token 用量是逐文件探索的十分之一,工具调用次数砍到原来的 2.1 分之一。
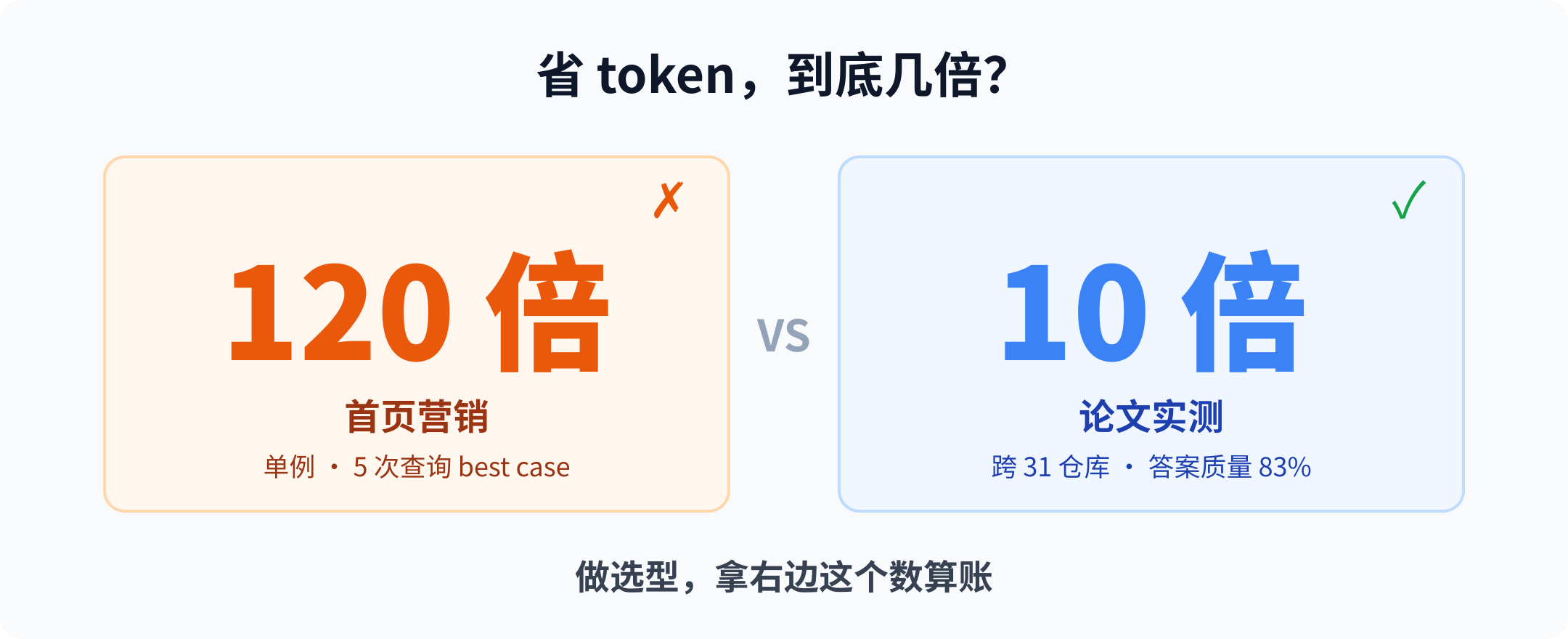
10 倍和 120 倍,差了一个数量级。这个差来自样本:首页那条是单次查询挑出来的极值,论文那组是 31 个仓库平均后的常态。做技术选型,永远拿后者算账:看到任何工具首页挂着"省 99%"“快 100 倍”,先别激动,去翻它的 benchmark 怎么测的、测了几个 case。单例的极值和跨样本的均值,从来不是一回事。
但话说回来,就算只剩 10 倍、答案质量只剩 83%,对天天拿 Agent 刷大仓库的人,这账也值得算:读结构这块的 token 砍掉九成、工具调用砍掉一半,同样的预算和延迟下,Agent 能把省出来的额度匀去干正事。
它擅长什么,又帮不上什么
看清机制,就知道它的边界画在哪。
它索引的是结构,不是语义。所以它擅长关系类、影响类的问题:谁调用了这个函数、改这行波及哪些服务、这仓库分了几层、哪些是死代码、跨服务的路由怎么连。这些本就是"查关系"的活,图天生比逐文件读快一个数量级。
但意图类的问题它帮不上。“这段逻辑为什么这么写”“这条业务规则对不对”“边界条件考虑全了没”——这些得真读源码、真理解上下文,图只告诉你 A 调用了 B,不告诉你 A 为什么这么调。这类活它一行也替不了你和模型去读。
还有个容易被忽略的设计:它自己不带 LLM。别的代码图工具往往内嵌一个模型,把自然语言翻成图查询,于是又得配 API key、又多一层成本和延迟。这个工具只做结构分析的后端——解析、建图、查图,翻译那一步交给你本来就在用的 Agent。一个静态二进制,零运行时依赖,不要 Docker、不要 key,代码不出本机。
所以装它之前,先别纠结"它能不能省 token"——能。该掂量的是你和 Agent 的时间,到底花在哪类问题上。如果你大量在问"这玩意儿牵一发动全身动了哪些地方",这张图就是你缺的那块;如果你主要在啃业务逻辑、debug 一段诡异的实现,图帮你定位个入口,剩下的还得老实读代码。
把账算对、把边界画清,这工具就从"GitHub 又火了一个 MCP",变成你工具箱里一件知道什么时候该掏出来用的东西。
