
首页写省 120 倍 token,我翻了它的论文:跨 31 个仓库平均是 10 倍
GitHub 上又冒出来一个让我停下来的项目,叫 codebase-memory-mcp。
真正让我停下的,是首页那行加粗的数字:120x fewer tokens。它登顶 trending 我倒没太在意。再往下看一行小字,给了算法——5 个结构化查询大约 3,400 token,对应文件逐个搜大约 412,000 token。它甚至贴心地把这个换算成了"省 99.2%"。
省 99%。这个数字一出来,我没激动,先起了疑。
因为我太知道"AI 读代码"这件事有多烧钱了。你给 Claude Code 开一段新对话,让它在一个十几万行的老仓库里改个东西,它干的第一件事永远是把相关文件一个个 read 进上下文——这个函数谁调用了、改这里会牵连到哪、整个架构怎么分层,它没有记忆,每次都得从头读一遍。这部分 token 才是账单上最大的隐性开销,甚至比模型本身贵。所以但凡有工具号称能砍掉它,我都想看看是真的,还是又一句营销话术。
于是我做了件很无聊、但每次都该做的事:去翻它的论文。
把账算清楚之前,先看它怎么算的
它的 README 里埋了一句话,指向一篇 arXiv 预印本——《Tree-Sitter-Based Knowledge Graphs for LLM Code Exploration via MCP》。论文里有一组完全不一样的数字,是跨 31 个真实仓库实测出来的:
83% answer quality,10× fewer tokens,2.1× fewer tool calls。
10 倍。不是 120 倍。
我盯着这两个数字看了一会儿,心里"咯噔"一下——不是因为它骗人,恰恰相反,是因为它太诚实了。那个老老实实跨 31 个仓库跑出来的 10 倍,被它写进了论文;而那个 5 次查询凑出来、挑了个最极端样本算出来的 120 倍,被它加粗摆上了首页。
120 倍是怎么来的?它找了一个结构问题特别密集的场景——5 个查询全是"谁调用了它""架构总览"这种纯结构题,正好是图查询最擅长、文件逐读最吃亏的极端情况。这种 cherry-pick 不算造假,每个数字都真,但你不能拿它当日常。真到了你自己那个混着业务逻辑、混着"这段当初为什么这么写"的仓库里,10 倍才是你能落袋的数。
替它有点可惜。最硬的证据明明在论文里躺着,首页却非要摆一个一眼就让内行起疑的漂亮假象。
那 10 倍是从哪省出来的
把营销数字剥掉,机制本身是真东西,值得讲清楚。
传统 Agent 读代码是"逐文件探索":想知道一个函数的影响面,它得 grep 一遍、read 几个文件、再 grep、再 read,几十轮下来,上下文里塞满了原始代码文本。token 就是这么烧光的。
codebase-memory-mcp 换了个思路:先用 tree-sitter 把整个代码库做一遍 AST 解析,建成一张持久化的知识图谱。节点是函数、类、HTTP 路由,边是调用链、跨服务依赖;它连 Dockerfile、K8s manifest 都给你建成图节点。覆盖 158 种语言,对 Python、TS、Go、Rust 这些还额外挂了 LSP 做语义类型解析。
建好之后,"谁调用了这个函数"就不再是一轮轮 grep,而是一次图查询——官方给的数字是结构查询亚毫秒返回。Linux 内核那种 2800 万行、7 万 5 千个文件的怪物,全量索引也就 3 分钟。
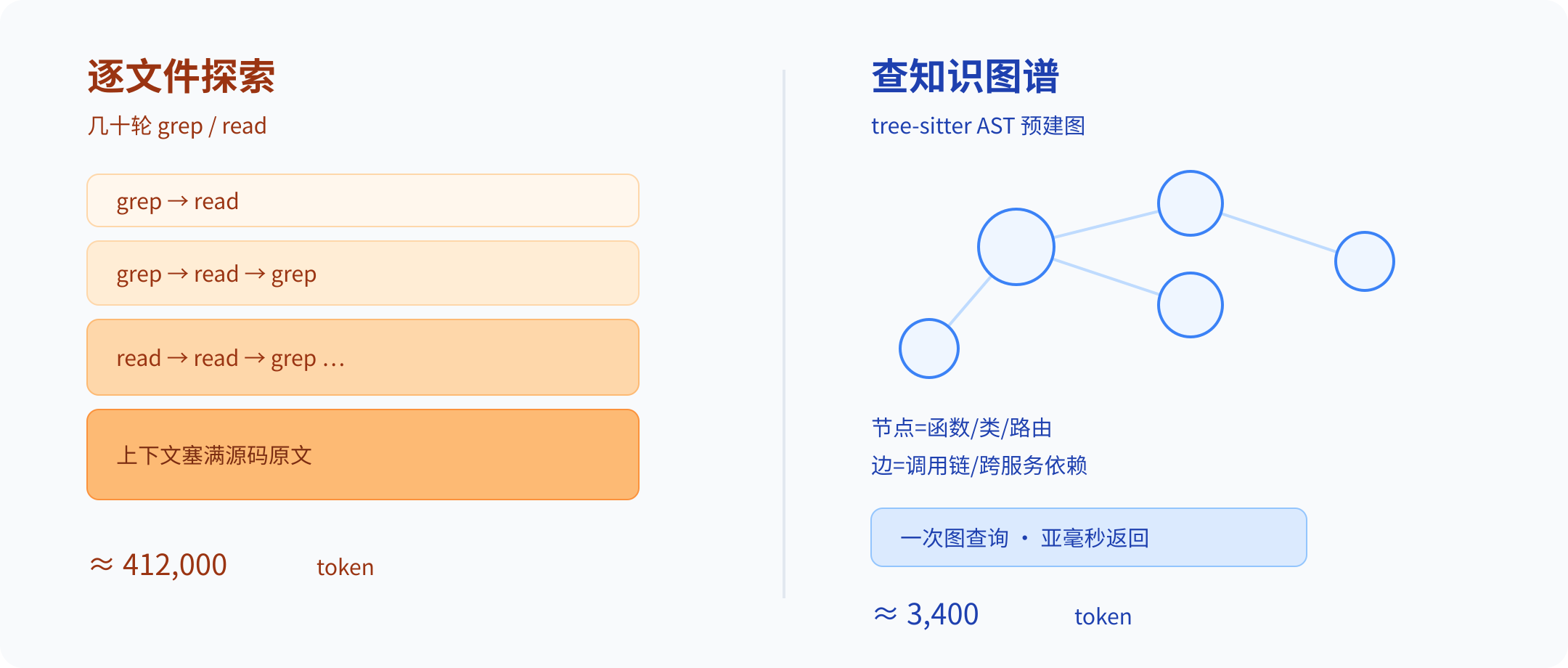
省 token 的逻辑就在这:你不再把文件原文喂进上下文,只把"结构答案"喂进去。10 倍的差距,本质是"读全文"和"查表"的差距。
它擅长什么,又帮不上什么
这是装之前最该想清楚的一件事,比那行命令重要。
它擅长的是结构、关系、影响类问题:谁调用了它、改这里影响谁、架构怎么分层、有没有死代码、跨服务的 HTTP 路由怎么连。这些是图天生能答的。
它帮不上的是语义、意图类问题:这段逻辑为什么这么写、这条业务规则对不对、这个 hack 当初是为了绕什么坑。图只索引结构,不替代理解——这些你还是得老老实实把源码读进去。
所以它要顶替的是 Agent 那几十轮无脑 grep,不是来替你读代码的。想清楚这个边界,你才知道自己那个仓库值不值得上。
真要试也简单,一行命令,它会自动探测你机器上的 Claude Code、Codex CLI、Gemini CLI 等 11 个 Agent 并写好各自的 MCP 配置,全本地处理,代码不出本机:
curl -fsSL https://raw.githubusercontent.com/DeusData/codebase-memory-mcp/main/install.sh | bash
最后
这个工具我会转给团队里天天用 Agent 刷大仓库的同事,但配的话不是"快去装,省 99% token"。
是这句:机制是真的,先把代码库建成知识图谱这条路走得通;但别信首页那个 120 倍,论文跨 31 个仓库实测是 10 倍——而 10 倍,已经够把你那张 token 账单砍下来了。
下次再看到哪个工具首页挂着一个夸张到反常识的倍数,别急着激动,也别急着划走。花五分钟翻翻它的 benchmark 到底怎么跑的——真东西经得起你这么翻,假象经不起。
