
每次翻 Agent 的生产事故日志,死的不是“模型把题答错了”。
是它先把推理写得滴水不漏,然后调用了一个不存在的工具名。或者工具返回了正确结果,它当没看见,继续沿着自己之前想偏了的方向往下推。
模型够聪明,但它太早把推理写死了:还没看清自己手里有哪些工具,就已经把路线规划完。
DeepSeek V3.2 这次发版,跑分我不关心。模型榜单每换一版都会重新排座位,今天领先、明天追平,最后很容易变成一场“谁比谁多 0.3 分”的围观。我在意的是技术报告里的另一行字:
“不同于过往版本在思考模式下无法调用工具的局限,DeepSeek-V3.2 是首个将思考融入工具使用的模型。”
翻译成工程语言:开源模型里,终于有一个能在推理的中途自己决定“该动手了”。
那道缝:想完了再去干
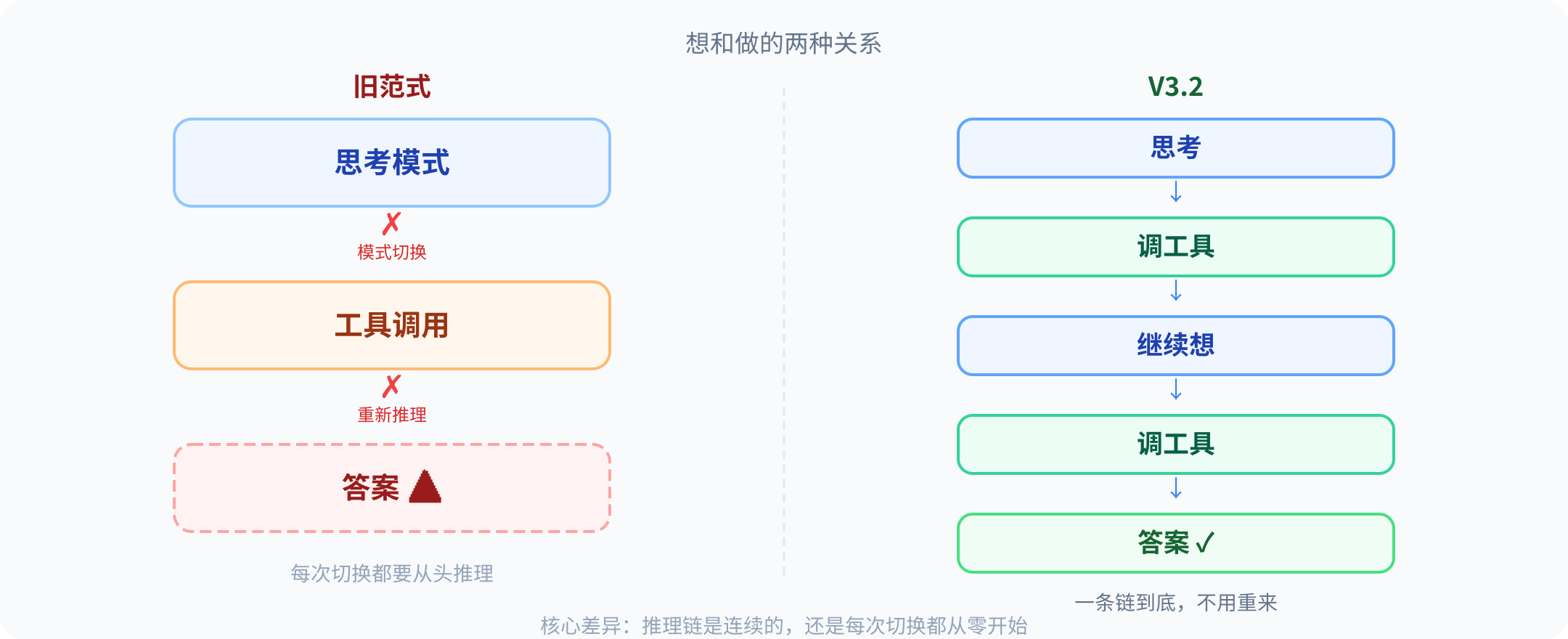
过往开源模型做 Agent 是什么样的?
模型接到任务,进入思考模式,开始推理:问题的结构、需要哪些信息、分几步。产出一段很长的思维链,漂亮、有条理。
然后它退出思考模式,进入工具调用模式。对着刚才那套推理,开始调 API、查数据库、读写文件。
问题出在“切换”那个动作上。
模型在思考的时候,根本不知道接下来能调用哪些工具——工具列表是外部系统在“思考结束”之后才注入上下文的。所以它的推理是盲推:它知道自己需要查天气,但不知道天气 API 的参数叫 location 还是 city,不知道返回值的字段名是 temperature 还是 temp。这些信息在它做决策的时候不在它的上下文里。
于是常见失败出现了:推理结构看似完整,执行阶段却对不上真实工具接口。
更致命的在后面——工具返回了结果。模型需要把结果“接回”推理链,判断这结果意味着什么、下一步要不要调整。但此时思考模式已经结束,它只能基于工具返回的几行 JSON 做一次新推理。刚才那些假设、分支和未完成的判断,很容易在工具调用边界上断掉。
这就是那道缝。思考归思考,执行归执行。中间靠 Agent 框架硬搭桥,而桥的两头说的是两种语言。
生产 Agent 最难排查的,往往不是最终答案错了,而是中间状态断了:上一步看似成功,下一步却没有拿到真正可用的结果;任务已经完成,模型还在沿着旧计划继续执行。模型会答题,不等于它知道自己做完了什么、下一步该不该继续、结果有没有写回状态。
Agent 的关键分水岭:推理过程中能不能及时确认现实。
V3.2 把缝补上了
V3.2 的关键变化在架构层:让推理链和工具调用共享上下文。
它的 API 里有一个关键设计:思考模式下做工具调用,reasoning_content 会在所有子请求中持续回传。模型想的每一步思维链,都跟着工具调用一起流转——调完一个工具,“刚才想到哪儿了”不会丢,直接接着往下想。
看一遍 API 流就清楚区别了:
模型接到“查杭州明天天气” → 第一步思考“我需要先知道明天的日期” → 调用 get_date → 拿到 2026-04-20 → 基于这个结果继续思考“好,明天确定了,查杭州” → 调用 get_weather → 拿到“多云 7~13°C” → 继续思考“整理一下告诉用户” → 输出最终回答。
三次思考之间是连续的一条链,不是分别重启的三段。每一步工具调用的结果,都直接插进推理的半途,模型可以据此修正后续判断——查完发现只有 7 度,它在最后输出的那一步,才会自然地补一句“带件薄外套”。
工具调用不再是推理结束后的外部动作,而是推理过程中可被模型主动选择的一步。
官方还提到一组训练数据:1800+ 种环境、85000+ 条指令做的强化学习,逻辑是“难解答,易验证”——给模型布置它必须查资料才能完成的题,但对错可以自动判断。模型没法靠死记硬背过关,只能学会一件事:在正确的时间伸手。
这两个数字我没法独立复现,所以我不会把它写成“DeepSeek 已经解决 Agent”。对开发者更有用的判断方式,是把它放进自己的工具链里跑三类小题:
| 要测什么 | 好信号 | 坏信号 |
|---|---|---|
| 调用时机 | 模型在缺信息时很早停下推理,先查工具 | 先写一大段方案,最后才想起查 API |
| 参数对齐 | 调工具前已经看懂工具名、参数名、返回结构 | 调用不存在的工具名,或把 city、location 混用 |
| 结果回接 | 工具返回后能修正后续判断 | 查到了结果,但继续沿着旧假设往下写 |
我会把这三类叫做:拖延型、幻觉型、断线型。V3.2 如果真把 thinking 和 tool use 缝到一起,最先改善的就应该是这三类错误,而不是榜单上多赢几道题。
把它放到开源 Agent 生态里看,位置也更清楚:GLM-5.2 更像是在智力和上下文长度上往上顶,Kimi K2 系列更像是在成本和输出效率上往下压,DeepSeek V3.2 这次切的是执行通道——模型能不能在推理中途决定动工具。三条线都重要,但解决的不是同一个问题。
不用上复杂 benchmark,三条本地小任务就够看出味道:
- 给它一个只靠当前上下文答不出的版本号问题,看它是在承认缺信息后立刻查,还是先编一段历史背景。
- 给它两个名字相近但参数不同的工具,比如
search_docs(query)和read_file(path),看它会不会把参数混着填。 - 让工具故意返回一个和它预判相反的结果,看它是否改结论,还是继续沿着原来的假设往下写。
如果模型在这三条里分别表现为:拖到最后才查、调用不存在的字段、查完仍然不改答案,那就说明它还没有真正把工具结果接进推理链。分数再漂亮,进生产也会变成日志里的红字。
不完美,但对的方向
官方公告里写了一句很诚实的话:V3.2 的思考模式工具调用“未充分适配 Cline、RooCode 等使用非标准工具调用的组件”。意思是模型本身会了,但周围的工具生态还没跟上——大多数 Agent 框架和插件还在用“先想完再调工具”的老假设。
所以 V3.2 现在最顺滑的体验,仍然会在支持这套调用方式的 API 和工具链里。放到第三方框架里,兼容性问题仍然会出现。
判断自己有没有中招,也不要只看模型名。先看你用的框架是否支持这套思考中调用工具的格式,尤其是那些非标准工具调用组件。遇到工具结果接不回后续回答的表现,先别急着骂模型,先查框架有没有把 reasoning 内容和工具结果一起回传。
但这不妨碍方向是对的。因为这道缝——“想”和“做”之间的那道缝——才是 Agent 在真实环境里最常翻车的地方。不是模型不够聪明,是它不知道什么时候该停止空想、伸手去查。
下次看 Agent 模型发布,换一个问题
Benchmark 跑分只回答一件事:模型最终答对了没有。
但任何跑过生产 Agent 的人都知道,最终答没答对,只覆盖了一部分成功率。真实环境里,更大一部分取决于这几个问题:
模型在第几步意识到自己该动手了——是写完一大段方案才想起来可以调个 API,还是很早就发现“这个信息我脑子里没有,得去查”?
它调的工具对吗——不光是有没有调,而是调的时候,参数名和返回值结构是不是它推理时就已经在考虑的那些?
工具返回的结果它真的用了——最隐蔽的坑:模型调了工具、拿到了结果,但继续沿着调用之前已经偏掉的推理方向走。查回来的东西被扔在一边。
这三个问题,没有一个能在标准 Benchmark 表格里找到答案。但它们才是 Agent 能不能跑生产的真实分水岭。
所以我今天不会给 V3.2 打一个“值得迁移”的分。没有真实 API 日志、没有同一套工具链下的对照测试,就不要假装自己已经实测过。更稳妥的做法是:先拿上面三类任务测一轮,再决定它适合放在搜索、代码修改、自动化流程,还是只适合继续当一个聪明的聊天模型。
V3.2 的意义不是“又多了一个能跑 Agent 的开源模型”。是开源模型第一次在训练阶段就把“什么时候该调用工具”当成一个需要学习的能力,而不是一个外部系统的调度逻辑。把曾经过往版本里那道“先关了思考再开工具调用”的缝,从架构层补上了。
评估 Agent 模型时,先跑工具调用链路测试,再看 benchmark。API 文档里那条推理链和工具链怎么接,往往比榜单名次更早暴露它能不能进生产。
