
两个模型
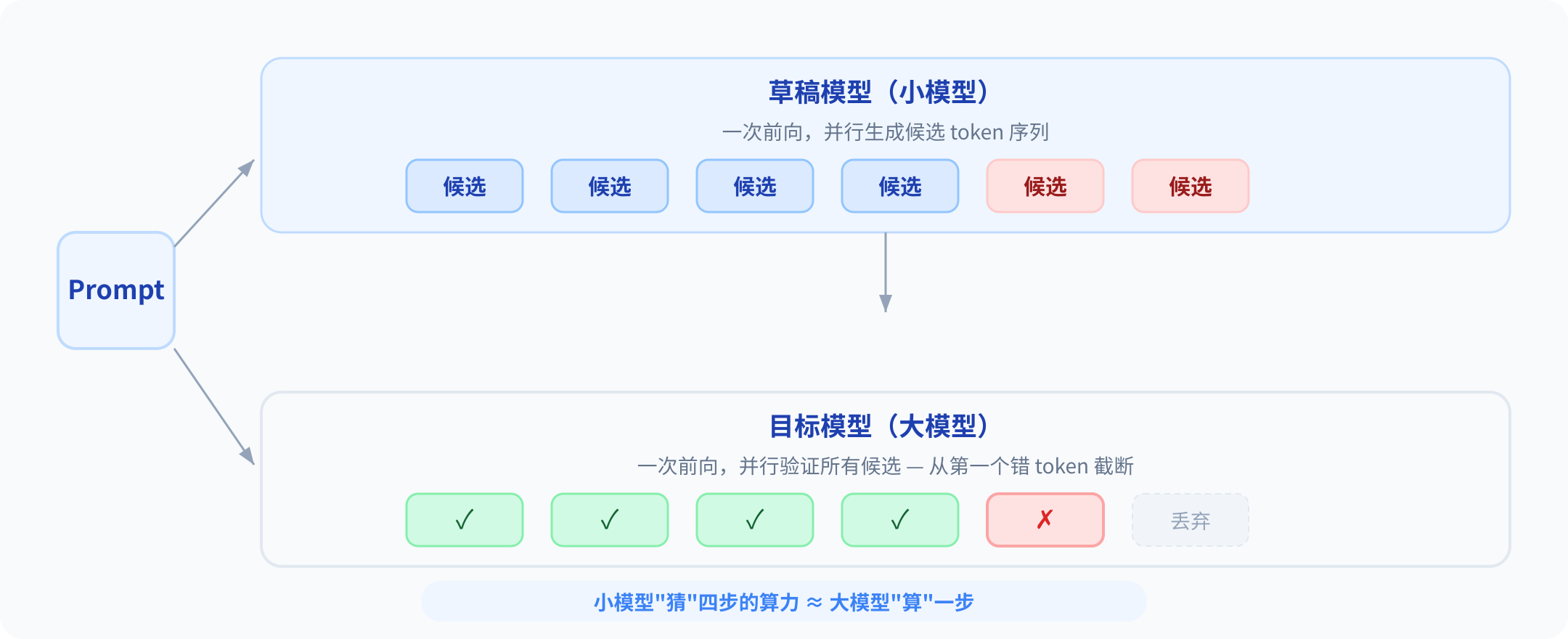
你调 DeepSeek API 的时候,后面其实一直有两个模型在跑。一个大模型,一个小模型。大模型不自己逐字算——它拿小模型先猜好的一串候选 token,从头开始审。猜对的直接过,第一个猜错的就扔掉后面全部,大模型自己补上。
这个过程在学术圈里叫推测解码。名字唬人,逻辑简单:用低成本"猜"替代高成本"算"。
半个世纪前 CPU 就在玩同一套
1993 年,奔腾处理器第一次把分支预测做进了大众市场。CPU 不等前面指令算完,先猜下一条走 if 还是 else,流水线照常跑。猜错了,冲掉错误路径上的中间结果,从正确地址重新取。到奔腾 Pro,乱序执行补上了更激进的一步——连"哪条指令先算完"都不等了,后面的指令只要不依赖前面的结果就先投机执行,算完暂存着,等前面确认了再按正确顺序提交。
半个世纪,“猜+验"这套方法论在 CPU 里被证明是正确的,甚至是唯一正确的。现在它移植到了 LLM 推理上,赌注从"下一条指令走哪条分支"换成了"下一个 token 是什么”。
同一个套路,CPU 用了几十年。区别只有一个:CPU 里的分支预测器和乱序引擎是 Intel/AMD 焊死在硅片上的,你换不了。但 LLM 推理里负责猜的那个小模型,是可以换的。
草稿模型的归属权
DeepSeek 把 DSpark 的草稿模型 checkpoint 放在了 HuggingFace 上。训练代码(DeepSpec)也开源了,里面不光有 DSpark,还有 DFlash 和 Eagle3 两个竞争方案的完整实现。一份训练配方:130 万条 prompt,Qwen3 系列做目标模型,10 个 epoch——你可以拿自己的数据照跑。
以前调 API,推理管线的最后一步——用什么草稿模型、怎么训、怎么调度——全在厂商机房里,你看不到。DeepSeek 是第一个把这一步拆出来、放上桌面的厂商。
而且它是真的在生产环境里跑了才开源的。根据他们论文里的数据,DSpark 上线后,在相同吞吐量下,V4-Flash 每用户生成速度提升了 60% 到 85%,V4-Pro 提升了 57% 到 78%。在一个严格限时(比如 120 tok/s/user)的场景下,老的基线几乎撑不住并发,而 DSpark 把存活区间硬生生撑开了。
这件事的后果不是"推理加速了",是你开始有了选择——你能自己训练草稿模型、针对自己的业务场景调优、甚至给不同用例配不同的小模型。
推理管线的架构权,第一次从厂商机房往外移了一步。
AI 不会写内核,但很会投机
这周同时发生了另一件事。ParallelKernelBench 测了 87 个真实的多 GPU CUDA 内核任务——让 AI 从 PyTorch + NCCL 出发,写出能直接走 NVLink 通信的高性能内核。
结果硬得很:最强模型(GPT-5.5)87 个任务只解了 28 个,其中只有 22 个比 PyTorch 基线更快。给它编译反馈多试几轮,最多 35 个正确、26 个更快——快解率不到 31%。
AI 写不出高效多 GPU 内核的原因也不复杂:多 GPU 通信需要理解拓扑、同步语义、流水线编排,模型在这块几乎没见过训练数据;出了问题不会 debug,给反馈也最多改改语法错误和 shape 不匹配。
但你往回看一层,AI 在做推理加速这件事上用的招,本质上就是投机执行——和 CPU 的分支预测一模一样。它不会写 NVLink 上的 all-reduce 内核,但它会在推理时用一个小模型把你每轮验证能吃的 token 数从 5 个拉到 6 个,延迟砍掉一半。
我读这两件事放在一起的感受是:底层硬优化仍然卡在人手里,但上层的投机策略已经有成熟可换的零件了。
下次聊推理成本,换个问题
之前我把推理服务切到 DeepSeek 的时候,只看了两个数:每百万 token 多少钱,首 token 延迟多少。跟大部分人的比价逻辑一样。
现在我多了一个问题:草稿模型怎么训的,我能换自己的吗。
这个问题比"你用什么 GPU"更管用。GPU 决定的是物理上限,草稿模型的归属权和实现水平决定你能拿到上限的多少。
翻一下论文里的数据就清楚。Qwen3-4B 做目标模型,DSpark 在数学推理上的 average accepted length 是 6.11——大模型每验一次平均吃进 6 个 token。纯自回归草稿(Eagle3)是 5.14,纯并行草稿(DFlash)是 5.40。差出来的这个 token,就是架构设计和训练投入换出来的。而且差距随模型变大而拉大——Qwen3-14B 上 DSpark 比 Eagle3 领先 30%。
前沿模型只会越来越贵。模型越贵,猜对一个 token 的价值越大。推测解码给你省下的钱,和模型本体的推理成本成正比。
当然这不是免费午餐。草稿模型本身也要吃算力,对于那些天然低接受率的请求(比如开放聊天),这份开销等于白扔了。论文自己也提了这一点——这是 DSpark 目前最大的局限。但这件事的框架意义比单个算法重要:它说明推理加速的竞争,已经从"谁有更好的 GPU"进入了"谁的草稿模型更聪明"。
草稿模型的归属权,正在变成 API 厂商之间一道新的技术围墙——同时也是部署侧第一次能伸手推一推这道墙。
