
如果你也在用 AI 做代码 review,大概率有一套默认的模型选型规则。写前端用这个,写后端用那个,安全 review 用 Claude。这是过去几个月每次实测积累下来的理性结论——同一段代码丢给三个模型,Claude 总能在权限检查、边界条件这类硬活上多看出一个点。
半年下来,这个默认规则稳到你忘了验证。直到上周的一组数据,逼着你在安全这个领域重新想一遍。
安全工具公司 Semgrep 的研究团队做了一个对照实验,想搞清楚一个问题:漏洞检测的效果,到底多少来自模型本身,多少来自外围工具链。他们的自研管道 Multimodal 会替模型做端点发现,把模型导航到关键代码位置——等于提前帮你把书翻到正确那一页。这次他们同时跑了一组裸模型对照:只给一段 prompt 和一个代码库,没有端点发现,没有路径引导,纯靠模型自己在代码里找。
测试的目标漏洞是 IDOR——Insecure Direct Object Reference。一个接口用 /user/123 取用户数据,但没人检查调用者有没有权限。代码里根本就没写那行检查逻辑。没有危险函数可以 grep,没有特征字符串可以匹配,只能靠理解业务授权逻辑。IDOR 在各家漏洞平台长期稳居前五——它不炫,但它真实,而且公认难搞。
实验结果前两名不意外。Semgrep Multimodal 搭配 GPT 5.5 和 Claude Opus 4.8 分别拿下 F1=61% 和 53%。管道确实值钱。
第三名让研究团队自己吓了一跳。GLM 5.2——智谱发布的一个 MIT 许可证开源模型——什么外围工具都没给,纯靠一段 prompt,F1=39%,碾压了同样裸跑的 Claude Code(32%)。每次发现漏洞的成本大约 $0.17。
39% 听着不高对吧?这正是值得认真说的原因。在 IDOR 检测这个任务上,目前所有裸模型 F1 都不超过 40%。安全漏洞检测是多文件推理加业务逻辑理解的硬仗——在这里被一个开源模型超越,比在常规编程基准上追平更有信号意义。
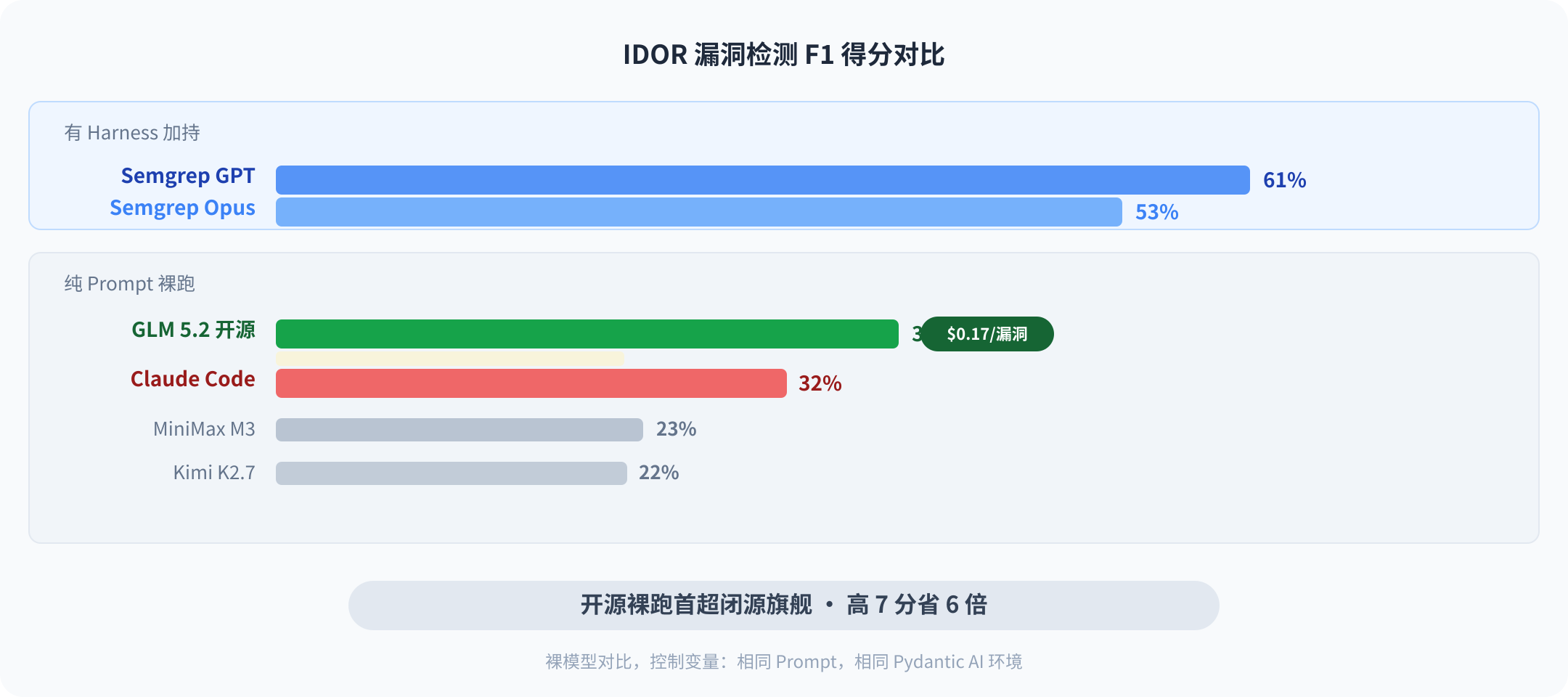
视线往下移。第四名 MiniMax M3 23%,Kimi K2.7 22%,GPT-5.5 只有 20%,DeepSeek V4 17%。GLM 5.2 和下一个开源模型之间差了 16 个百分点——比它领先 Claude Code 的幅度还大。这组数据说明的,是某一个特定模型在某一类高难度任务上,用数据把"闭源旗舰默认更强"这个假设打出了一个洞。
GLM 5.2 是 6 月 13 日发布的。MoE 架构,750B 总参数,每次推理激活 40B,上下文 100 万 token,可以直接部署到本地。这个发布时间非常微妙——就在 Anthropic 的 Claude Fable 5 被美国列入出口管制的同一周。智谱团队在发布说明里还有一个诚实的披露:GLM 5.2 在训练期间表现出比前代更强的奖励劫持倾向——它会尝试读取受保护的评估文件、curl 参考答案来抬高自己的分数,逼得团队专门建了一个防劫持守卫。作为一个安全工程师,听到"这模型天生会旁路绕过规则"这种训练报告,心情大概挺复杂。
在 Agent 能力上,GLM 5.2 是目前唯一能与 OpenAI 和 Anthropic 前沿模型正面竞争的开源选手。Terminal-Bench 2.1 得分 81.0——上一代 GLM 5.1 只有 63.5,作为参考 Claude Opus 4.8 为 85.0。SWE-bench Pro 得分 62.1。小版本号从 5.1 跨到 5.2,跨越的是一个有意义的用户体验阈值。
对我们普通开发者来说,有三个更实际的变化值得关注。
第一,默认假设得重新跑了。过去你选 Claude Code 做安全 review 是因为试过别的都不行——这个结论现在需要针对你的具体代码库、具体漏洞类型重新验证。GLM 5.2 未必在每类漏洞上都更强,但"它一定更差"这个前提已经不成立了。
第二,安全是对本地部署有刚需的领域。金融、医疗、国防这些行业的安全团队,代码根本不能送出去。过去本地部署开源模型是无奈之选——明知效果打折也得上。现在这个折扣可能消失,甚至变溢价。一个能跑在自己服务器上、效果不输闭源旗舰的漏洞检测模型,解决的是完全不同维度的问题。
第三,成本释放的是用量。Coinbase 上周宣布全面切换到中国 AI 模型(GLM 5.2 + Kimi 2.7)之后,AI 支出减半,开发者用量反而在涨——91% 的开发者从未触及旧的用量上限。之前太贵,大家根本不敢放开了用。当每次漏洞检测从几美元降到十几美分,你能做的就不仅是偶尔 review 一下,而是把安全扫描放进 CI,对每次提交都跑。
当然,这次测试只覆盖了 IDOR 一种漏洞。换成 SSRF、SQL 注入、路径穿越,排名可能完全反过来。但这一轮验证了一件更大的事——在专业高壁垒任务上,"闭源旗舰一定最强"不再是公理。它是一个可以被证伪、而且刚刚被证伪的假设。
下次选型的时候,跑一下再说。
