
同一句 prompt:“用 pnpm 建一个六边形扫雷游戏。”
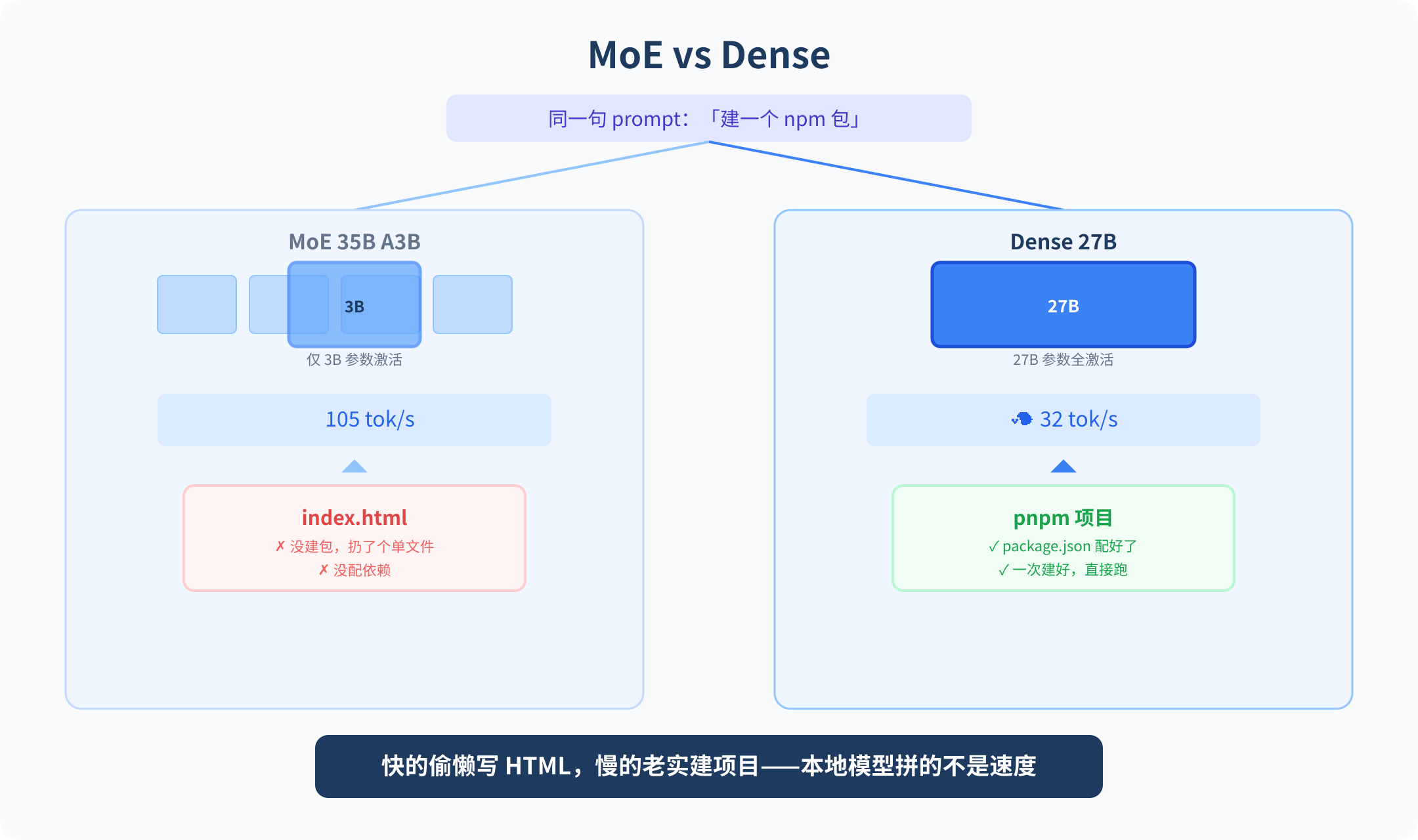
MoE 版本跑得飞快。但它把"建 npm 包"这条核心指令吞了,塞回来一个 index.html。
Dense 27B 慢了整整三倍。但它建了项目、配了 package.json、写了能跑的代码。一次通过。
过去两年,MoE 一直被视为本地模型的默认路线。逻辑很直——模型太大塞不进显存,那就每次只激活一小部分参数。Mixtral 这么干,DeepSeek 这么干,Qwen 这次也做了 MoE 版:35B 的总参数量,每次只激活 3B,llama.cpp 上跑到 105 tok/s——比很多云 API 还快。
速度上来了,指令遵循掉的却不是一个量级。你让它建项目,它写个 HTML 应付。你让它配依赖,它直接忽略。MoE 为速度牺牲掉的,恰恰是"理解你到底要我干什么"这个内核。
Dense 27B 走了条笨路:全部参数全程参与推理。Q8_0 量化后在 M5 Max 上 32 tok/s,Nvidia 消费卡上能到 50 tok/s。不够快,但够真。代码质量、多步骤任务、对模糊指令的拆解——MoE 版和 Dense 版之间,隔着一道能不能干活的鸿沟。
有人在 AI 开发者聚会上当场出 prompt:做一个蜡烛店落地页。几分钟跑出完整页面——响应式、默认样式体面、全部功能都在。云端模型做这些毫不稀奇。特别之处在于:它在你的机器上跑,开源权重,离线可用,代码不出你的硬盘。
所以推荐直接走 llama.cpp,跳过 Ollama 中间层。下载 GGUF 量化文件,一行命令起 server:
llama-server -hf unsloth/Qwen3.6-27B-MTP-GGUF:Q8_0 \
--spec-type draft-mtp -ngl 999 -fa on -c 65536 --port 8080
然后在 OpenCode 里配个 provider 就直接用。64GB MacBook 跑 Q8_0,32GB 换 Q4_K_M,24GB Nvidia 卡也能塞进去。
本地编码模型的竞争单位已经从参数榜、跑分、tok/s,变成了一个更朴素的指标——你告诉它"建一个 npm 包",它到底给你建了没有。看走眼成本很高:过去一年不少开发者试了本地模型又放弃,大概率碰上的就是跑分漂亮但指令遵循掉链子的 MoE 版本。它跟 Dense 27B 在 benchmark 上的分差几乎可以忽略,真干活时的差距却是一道天堑。
模型跑起来的时候风扇狂转、键盘区烫手。以前本地模型最尴尬的地方是跑分好看、一干活就露馅。现在终于有模型到了"真干活时发烫"的水平——对一台写代码的机器来说,发热说明它在干活。
如果说之前对本地模型的感觉还是"好像有戏",Qwen 3.6 27B 是第一个让人觉得"能用了"的具体答案。在你自己的电脑上跑起来,把活干完了。
